
Vizij - What’s in a name?
“That which we call a face, by any other name would look as sweet.” - Shakespeare, probably
Seeing behind the face

What looks like one animated face is actually the final result of several layers working together:
- renderable shape properties discovered from the asset,
- low-level rig channels that can write those properties,
- higher-level authored controls such as blink, gaze, and smile,
- named states, motion clips, and graph-driven behaviors,
- a runtime that resolves all of those into one frame,
- an application shell that decides why the face should do anything at all.
Keep two app surfaces in view while you read:
tutorial-agent-faceshows the live result,vizij-authoringshows how that result is built and edited.
flowchart LR
live["Visible face in tutorial-agent-face"] --> anim["Animatable leaves from the imported face"]
anim --> props["PropsRig channels<br>/propsrig/..."]
props --> abstract["Abstract controls<br>custom plus standard"]
abstract --> poses["Poses and pose groups"]
abstract --> clips["Animation clips and tracks"]
abstract --> progs["Procedural programs"]
abstract --> direct["Direct runtime inputs"]
poses --> orch["Runtime orchestration"]
clips --> orch
progs --> orch
direct --> orch
orch --> host["Web app, service-backed app, or standalone app"]
That ladder is the rest of the walkthrough.
A face is made up shapes and their properties
At the lowest visual layer, a face is a hierarchy tree of shapes and their properties discovered from the imported asset.
In practice, we parse the tree for properties to control such as:
- transform components,
- material or shader parameters,
- morph targets and any other renderable property the renderer can move.
This is where the Blender export matters. Blender does not export “a smile” or “a blink” as first-class behavior. It exports shapes, meshes, weights, transforms, and related properties that can later be driven.
That is why the Face Elements surfaces in vizij-authoring matter so much. They show the leaves that actually exist in the face.
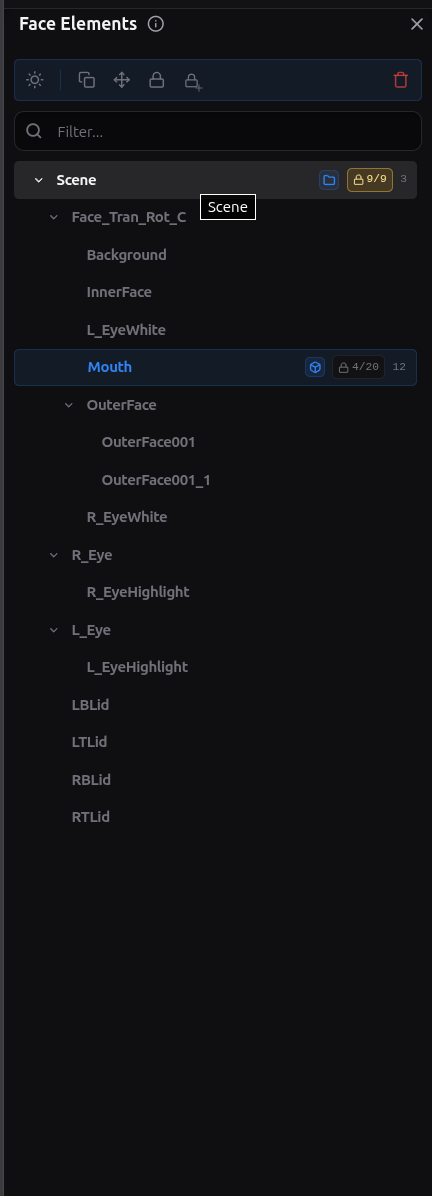
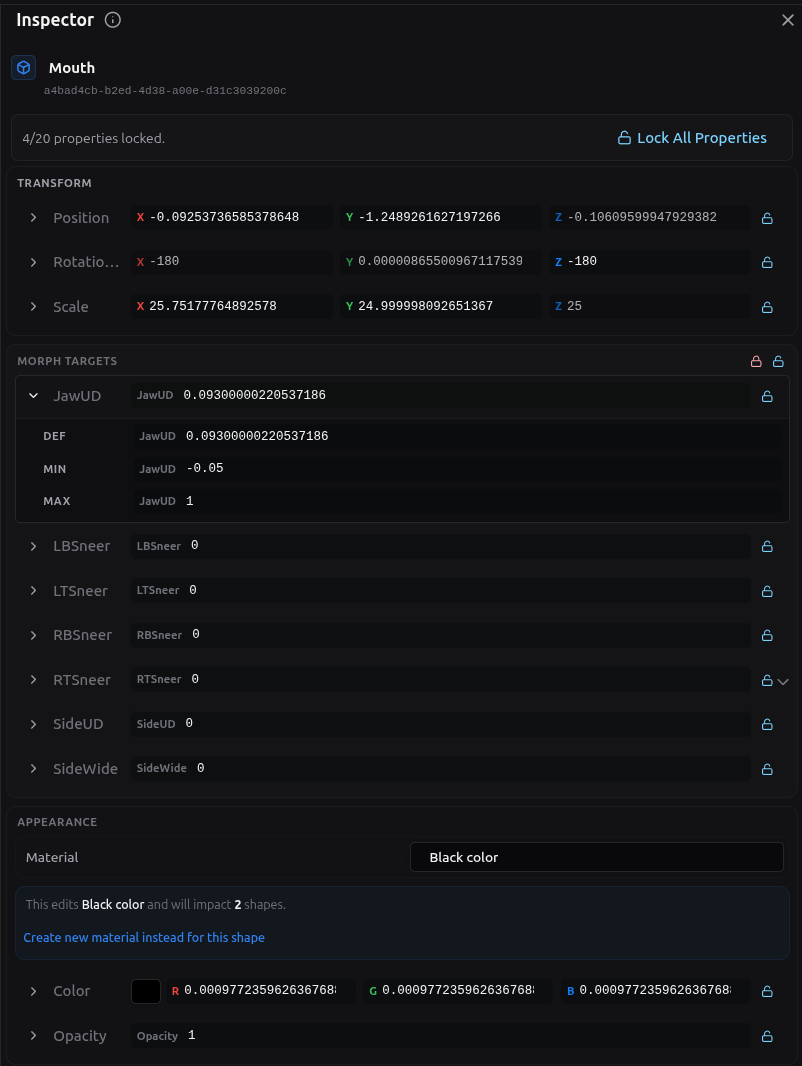
The important boundary is simple:
- animatable leaves are the renderer-facing sinks,
- they are real and necessary,
- they are too low-level to be the main control language for a face.
If you stop here, every behavior has to be expressed as raw property editing. Vizij adds rig layers above this so the same face can be controlled semantically instead of one property at a time.
”PropsRig”: the first drivable layer
We call the first driver layer above animatable leaves the property rig or PropsRig for short. By driver we mean something the user or system can control.
A PropsRig channel is a low-level rig variable created to write one animatable target or one precise part of that target. It is the first place where the system stops thinking in renderer internals and starts thinking in controllable inputs.
Every PropsRig channel carries the metadata that makes it usable:
- a stable path under
/propsrig/..., - a
minandmaxrange, - a
defaultValue, - the mapping back to the animatable property it ultimately drives.
In authoring, the canonical namespace is /propsrig/.... At runtime, that same authored path is resolved under the active face identity, so the write becomes part of the loaded rig/{faceId}/... space.
This layer is deliberately low-level. It is where you decide:
- what the allowable control range is,
- what neutral or default means for the channel,
- which exact face property the channel owns.
That makes PropsRig the right place for precise eye translation values, eyelid offsets, jaw offsets, and other direct ‘mechanical’ controls.
Locking also matters here. A locked face property or locked PropsRig target is treated as a sealed boundary while you are authoring. You can still read it and use it as the owned destination, but you do not add new child drivers underneath it until you unlock it. Unlocking means “this low-level channel can be restructured again.” Locking means “hold this boundary steady.”
So the PropsRig is the lowest level that is still meaningfully authorable:
- below it are scene leaves,
- at it are controlled rig variables with ranges and defaults,
- above it come the more semantic or abstract authored controls.
Abstract controls: blink, gaze, smile, and standard inputs
Above PropsRig sits the abstract driver layer.
This is where the face starts to feel like a face instead of a bag of numbers.
An abstract control is a higher-level authored input that can drive one or more PropsRig channels together. A blink control might move both eyelids. A gaze control might coordinate both eyes. A smile control might touch several mouth and cheek channels at once.
This is also where custom controls and shared controls meet.
Custom controls are face-specific. They exist because one face may need a control that another face does not.
Shared controls exist because it is useful for faces to expose common intent with a stable vocabulary. In current maintained language, that shared vocabulary is expressed through:
- standard controls,
- standard inputs,
- standard feature spaces.
Those shared control vocabularies are what let different faces answer to the same kind of intent even when the underlying meshes or PropsRig channels differ.
That matters for things like:
- blink,
- gaze,
- smile,
- mouth openness,
- other reusable face behaviors that applications want to ask for consistently.
The rule that keeps this layer clean is important:
- abstract controls can drive PropsRig channels,
- abstract controls can drive other abstract controls,
- abstract controls do not directly write animatable leaves.
That boundary prevents the semantic control layer from collapsing back into raw renderer editing.
Once this layer exists, a host application no longer has to know which exact eyelid weight or transform component should move. It can ask for a blink-like or gaze-like behavior and let the face’s mapping handle the details.
Poses: named states and blend groups
A pose is a named facial state defined over the control layer above PropsRig.
The key word is named.
A pose is not just “the current slider values.” It is a reusable authored state with a stable identity. That identity is what lets the same state be stored, blended, triggered, exported, and driven later in runtime.
The main parts of the pose model are:
- a pose id,
- the authored target values for the controls that matter to that pose,
- one or more pose groups,
- a weight that says how strongly the pose contributes.
Pose groups exist because several named states may need to blend locally before the larger system blends them with everything else.
The blend stages are:
- blend pose weights inside a group,
- compute a group result for each affected control,
- blend group results across groups,
- feed the resulting pose aggregate back into the control stack.
That is how Vizij keeps “smile,” “blink,” “viseme,” or other named authored states semantic without making them isolated presets.
This is the clean difference between a pose and the layers around it:
- PropsRig defines low-level controllable channels,
- abstract controls define semantic handles,
- poses define named states over those handles,
- pose groups define how those named states combine.
Because poses are weight-driven, they can coexist with direct control instead of replacing it. A runtime can keep a direct gaze input live while also blending an emotion pose or a speech-related pose on top.
Animations: motion over time
An animation is authored change over time.
If a pose answers “what state do I want,” an animation answers “how does the face change through time.”
The animation layer has a few core parts:
- a clip, which is the whole motion unit,
- tracks, which usually target one control path each,
- frames in time where the clip is evaluated,
- keyframes, which are the authored key points on the timeline,
- interpolation or transitions, which decide how values move between keyframes.
That means an animation is not just a list of values. It is a structured timed description of motion.
A clip can drive:
- PropsRig drivers,
- Abstract drivers,
- Pose weights,
- Future - other runtime-facing control paths that make sense for authored motion.
The transport in vizij-authoring exists to preview that motion the way a reader actually experiences it:
- play,
- pause,
- stop,
- seek,
- loop,
- inspect the timeline as it evolves.
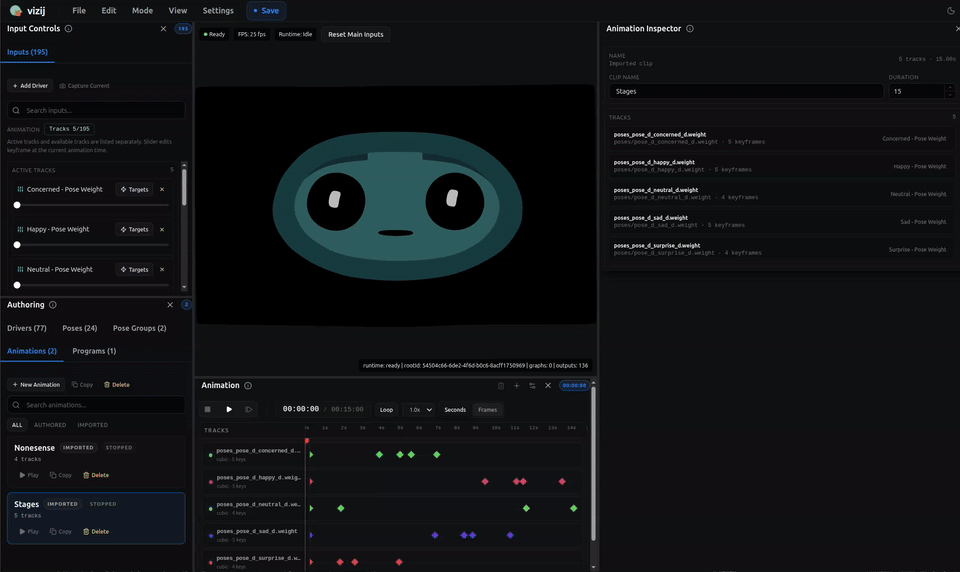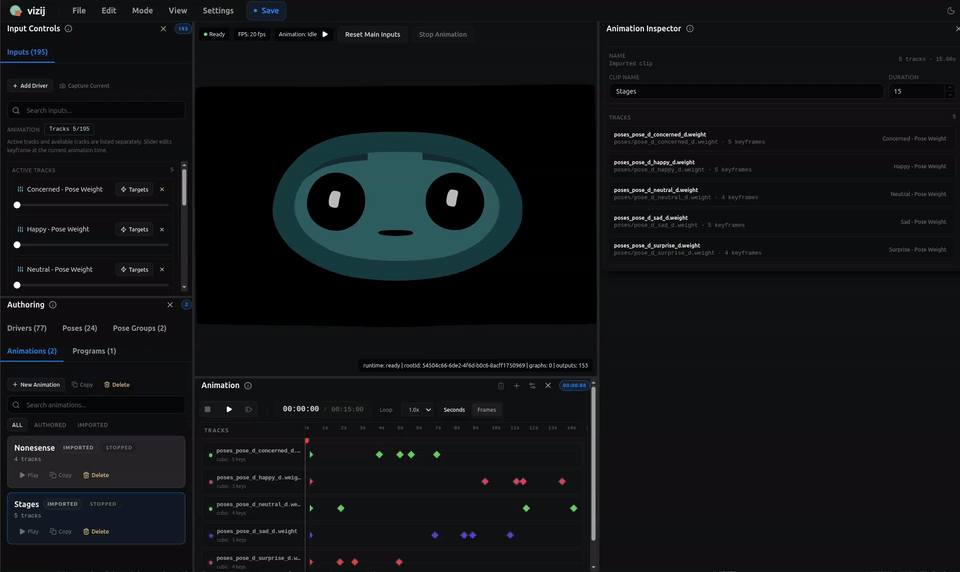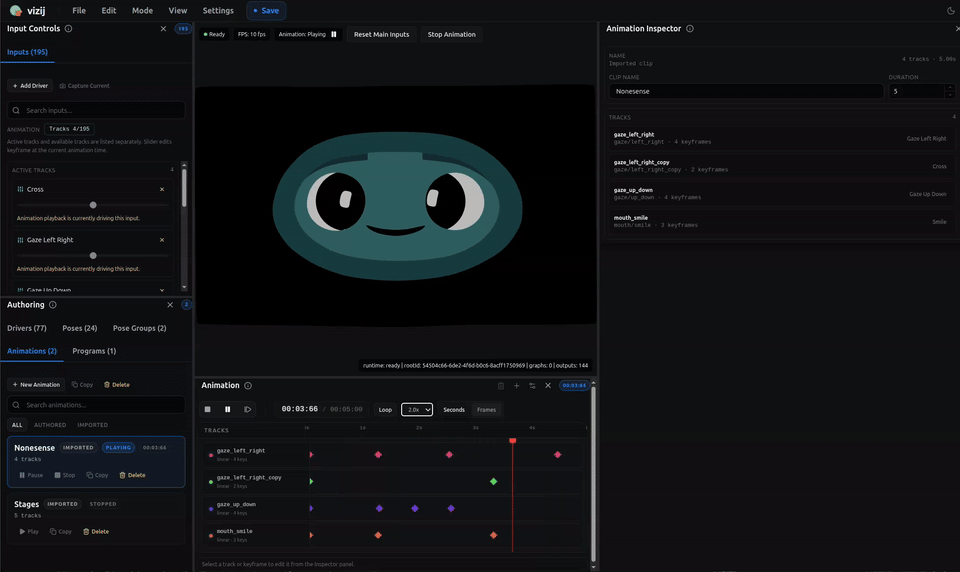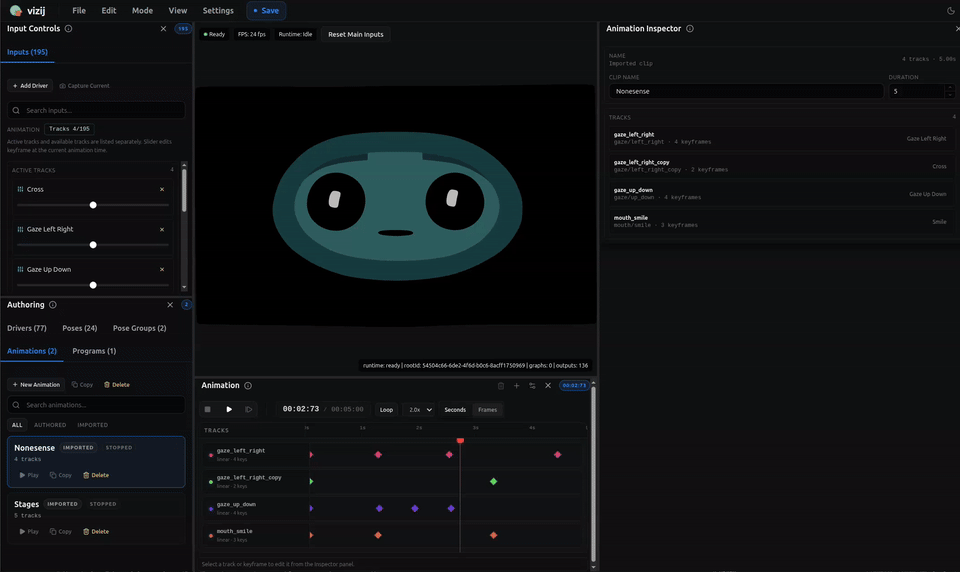
The important boundary is again simple:
- a pose stores a reusable state,
- an animation stores a reusable path through time.
You can animate into a smile, through a blink, across a viseme sequence, or between several expressions, but the thing that makes it an animation is still the timed structure of clips, tracks, and keyframes.
Procedural programs: graph-driven behavior
A procedural program is authored logic that computes driver outputs from inputs.
This is the layer to use when the interesting part is the rule, not just the state and not just the timeline.
The working pieces are:
- enabled inputs, which are the values the program is allowed to read,
- nodes, which transform or combine values,
- edges, which define how values flow between nodes,
- enabled outputs, which are the targets the program is allowed to drive.
That makes a procedural program different from both poses and clips:
- a pose stores a named state,
- an animation stores a timed motion,
- a procedural program computes behavior from current conditions.
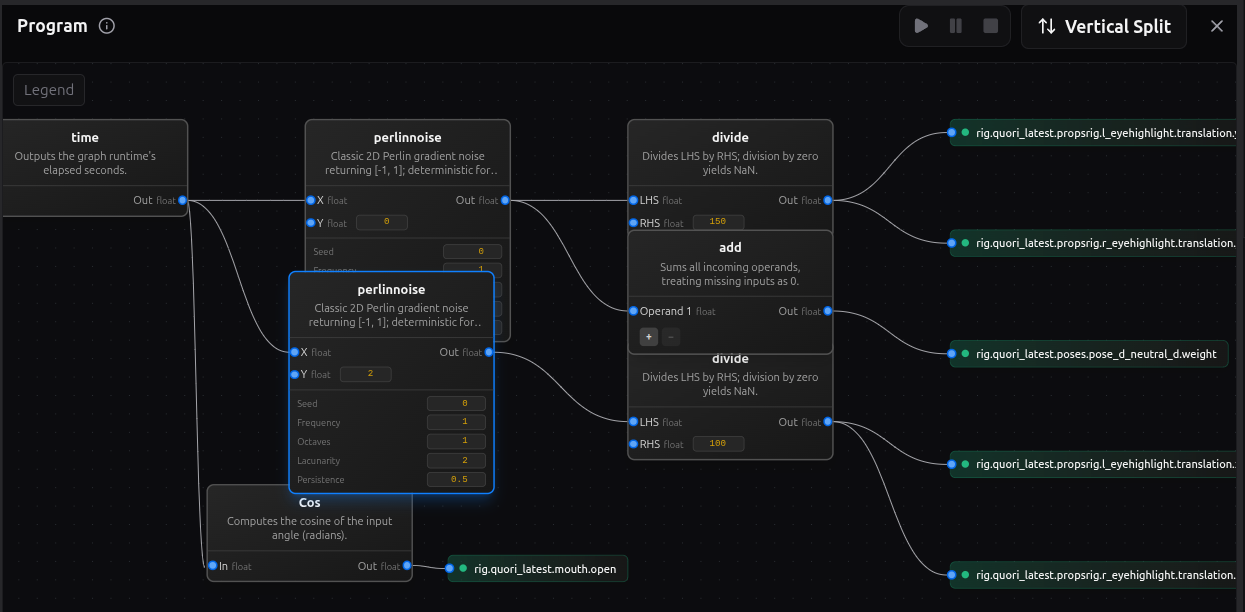
Use this layer when you want behavior such as:
- one value reacting continuously to another,
- a time-based oscillation without keyframing every beat,
- a thresholded or conditional response,
- a derived control that should keep responding while inputs change.
This is still authored behavior. The graph is designed in vizij-authoring, previewed there, and then handed to runtime as one more source of control logic.
Orchestration: how everything resolves together
Once direct controls, poses, animation clips, and procedural programs all exist, the runtime needs one place that resolves them into a single frame.
That job belongs to orchestration.
At runtime, several sources may want the face at once:
- a direct control from the host app,
- a pose weight change,
- an animation that is currently playing,
- a procedural program that is evaluating continuously.
Those requests do not jump straight to the renderer. They are staged, scheduled, merged, and then applied.
flowchart LR
direct["Direct app inputs"] --> orch["Orchestrator schedule and merge"]
poses["Pose weights"] --> orch
clips["Animation clips"] --> orch
progs["Procedural program outputs"] --> orch
orch --> merged["Merged writes for the frame"]
merged --> blackboard["Blackboard state"]
blackboard --> render["Renderer-facing values"]
render --> face["Visible face motion"]
The key concepts are:
- staged writes: requested values collected for the current frame,
- schedule: the order in which runtime controllers are evaluated,
- merged writes: the resolved outputs that survive conflict handling,
- blackboard: the shared path-value state that controllers read and write,
- renderer output: the resolved values finally applied to the loaded face.
The blackboard is the shared runtime memory of the current control state. It is what makes composition possible. One system can write a gaze input, another can react to it, another can blend animation over it, and the runtime still has one coherent place where that state lives for the frame.
This is also the layer that explains why tutorial-agent-face can stay clean. The agent demo does not bypass the face stack. It feeds requests into the runtime, and the runtime resolves those requests with the same orchestration model used for other authored behavior.
If you only remember one rule here, make it this one:
The visible face is the last proof in the chain, not the first. First the runtime stages and merges the frame. Then the renderer shows the result.
From runtime to application and deployment
Once the stack is authored, it can be hosted in different application shells without changing what a face fundamentally is.
flowchart LR
author["Authored asset and control stack"] --> bundle["Runtime bundle"]
bundle --> web["Minimal web app"]
bundle --> service["Service-backed app<br>tutorial-agent-face"]
bundle --> standalone["Standalone operator app"]
web --> controls["Direct UI and local control paths"]
service --> live["Live tool or session loop"]
standalone --> ops["Operator-facing launch and control surface"]
Three maintained deployment shapes matter most:
- a minimal web app, where the runtime loads the bundle and exposes direct control in the smallest believable shell,
- a service-backed app such as
tutorial-agent-face, where an external live loop asks the runtime to drive the face, - a standalone app such as
vizij-standalone, where the same runtime stack is packaged into an operator-facing surface.
The important rule is that deployment changes how requests arrive, not what the face is.
The face is still:
- animatable leaves,
- PropsRig channels,
- abstract controls,
- poses,
- animations,
- procedural programs,
- orchestration.
What changes from one application shell to another is the source of intent:
- a local UI can write direct values,
- a richer app can trigger clips, poses, or direct controls from a live session,
- a standalone deployment can expose operator controls and packaged runtime behavior without changing the lower layers.
That is why the same conceptual model carries from browser embedding to a desktop operator surface.
Beyond the maintained stack
Higher-level modalities still fit into the same ladder.
Camera-driven gaze can be understood as another source of gaze-related control requests. Audio-driven or LLM-driven behavior can be understood as another source of pose, animation, procedural, or direct-control requests.
What does not change is the stack underneath:
- the request still has to land on real controls,
- those controls still resolve through orchestration,
- the renderer still needs the same face asset and rig structure.
Behavior Trees are still proposal-level, not a maintained guidebook path. Treat them as a future way to decide when behavior should be requested, not as a replacement for rigs, poses, animations, programs, or orchestration.